Deep SAD: Deep semi-supervised Anomaly detection
이번 글에서는 ICLR 2020 에서 발표된 DSAD: Deep semi-supervised Anomaly detection 에 대한 후기이다. 이 글은 고려대 DBSA 연구실의 최희정 님의 발표 (https://www.youtube.com/watch?v=l–BSilQQqU)와 원 논문을 참고 하였음을 먼저 밝힙니다.
SVDD(Support Vector Data Description, 2004) 와 Deep SVDD(ICLR2018) 와 같은 알고리즘들이 널리 사용되고 있으며,
기존 SVDD 는 non-linearity를 추가 하기 위해 kernel을 사용하였다면, Deep SVDD 는 CNN를 사용하였음.
아래 (b)는 SVDD와 Deep SVDD에서 사용하는 unsupervised anomaly detection을 보여주며,
(f)는 Deep SAD에서 사용하는 semi-supervised anomaly detection을 보여줌.
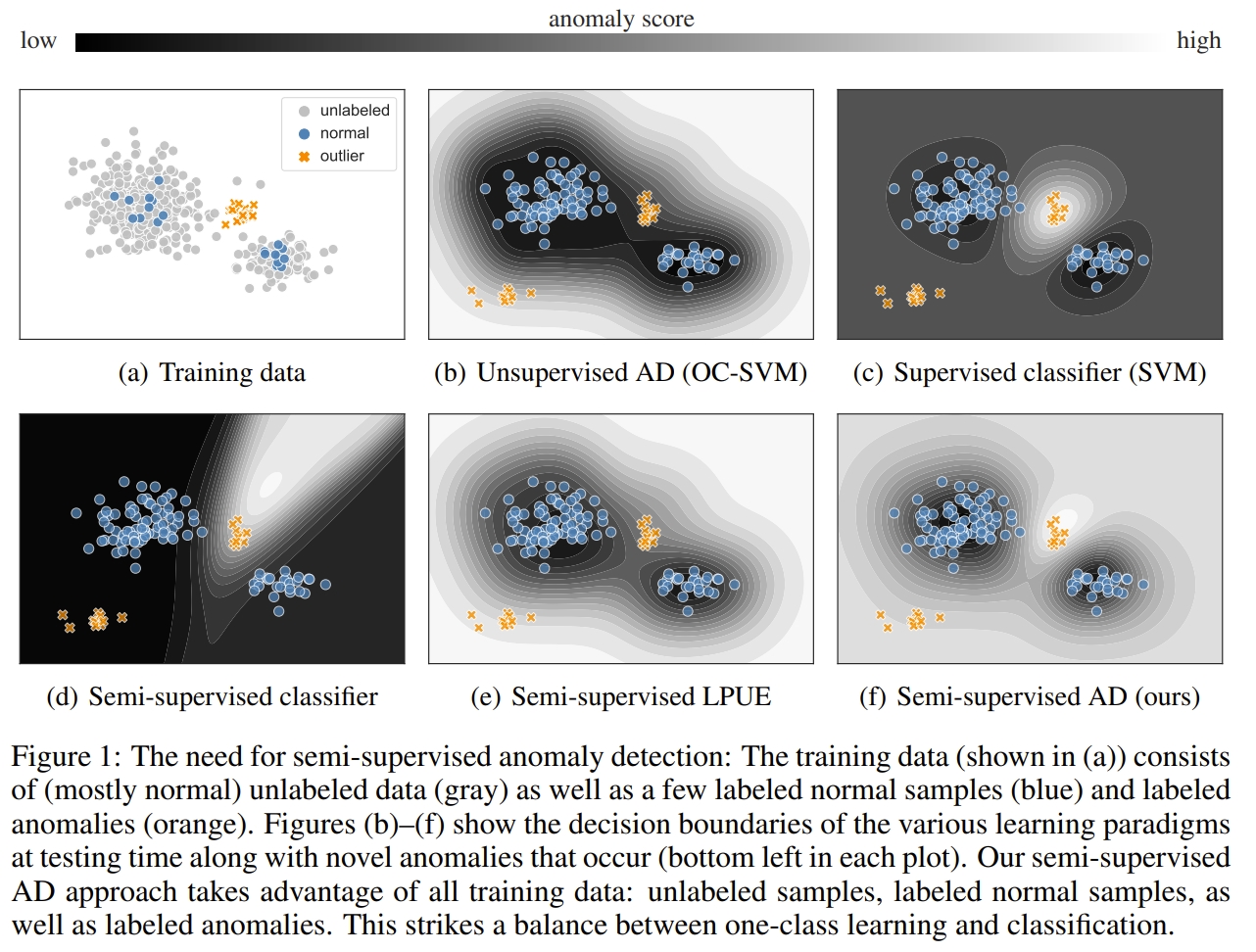
SVDD 의 목적은 Normal data를 포함하는 구의 크기를 줄이는 것을 목표로 함. slack variable term을 통해 일부 완화.
구의 반지름, 중심, soft margin에 대한 penalty을 학습함.
Deep SVDD 는 SVDD 와 유사하지만, 구의 반지름과 네트워크의 W만 학습함.
첫번째 term은 구의 중심과 data사이의 거리를 최소화 함.
W와 R을 교대로 optimization 함.
pre-trained CAE의 encoder weight를 W의 초기값으로 사용함. Bias를 사용하지 않음으로서 W와 R이 0으로 수렴하는 것을 방지.
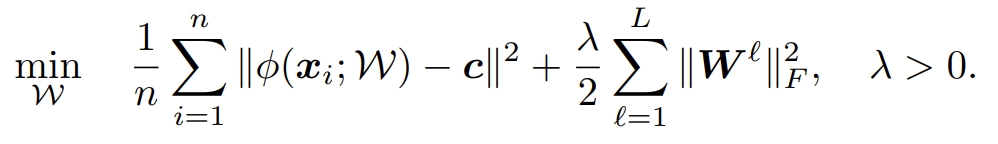
Deep SAD 에서 labeled 샘플이 없는 unsupervised AD (m = 0)인 경우, Deep SVDD와 같음.
pre-trained CAE에서는 normal sample의 latent는 구에 가깝게 (low entropy), Abnormal sample의 latent는 구에 멀리 (high entropy)라게 학습한
가중치를 초기값으로 사용.
unlabeled sample은 첫번째 텀으로 학습.
Normal sample (y=1)인 경우는 두번째 텀을 줄이도록 학습함. 즉, 구에 가깝게 학습함.
Abnormal sample (y=-1)인 경우는 두번째 텀이 역수가 됨. 구에 멀게 학습함.
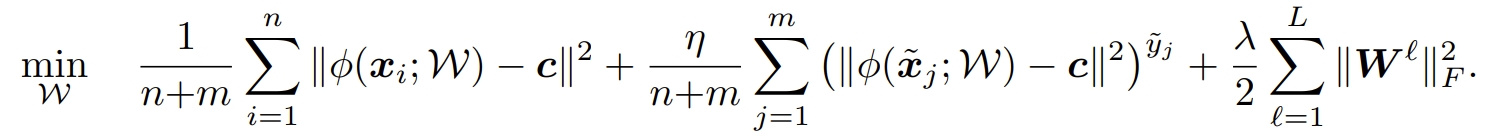
- Health care domain에서 Abnormal sample이 종종 보이는데, 이와 같은 샘플은 분류 시 애초에 제외 하는게 잘못된 판단을 내리는 것보다 더 좋아 보임.
Reference
Ruff, Lukas, et al. “Deep semi-supervised anomaly detection.” arXiv preprint arXiv:1906.02694 (2019).
(https://openreview.net/attachment?id=HkgH0TEYwH&name=original_pdf)